I wanted to make the GPT training pipeline feel less like a diagram in a paper and more like a thing I had actually touched. So I trained a small GPT model from scratch: 3.7M parameters, 21MB of Project Gutenberg text, and a few thousand lines of code around tokenization, checkpointing, training, sampling, and ablations.
The model is intentionally tiny: 4 layers, 4 attention heads, 256 hidden dimensions, context length 256, and about 3.7M parameters. The point was not to train a useful language model. It was to see which intuitions from large-scale LLM training still show up when the model is small enough to run in minutes.
That made the project more interesting than I expected. At this scale, some conclusions are obvious, but a few are not: raw loss can lie across tokenizers, width can beat depth, longer context can improve throughput, and being too conservative with the learning rate can hurt more than being slightly aggressive.
The Setup
The training corpus was a small collection of classic novels, including Les Miserables, War and Peace, Crime and Punishment, and Moby Dick. I used a byte-level BPE tokenizer, a GPT-2 style Transformer block, AdamW, cosine decay, and gradient clipping. The baseline ran for 10,000 steps on an RTX 4090 and finished in roughly five minutes.
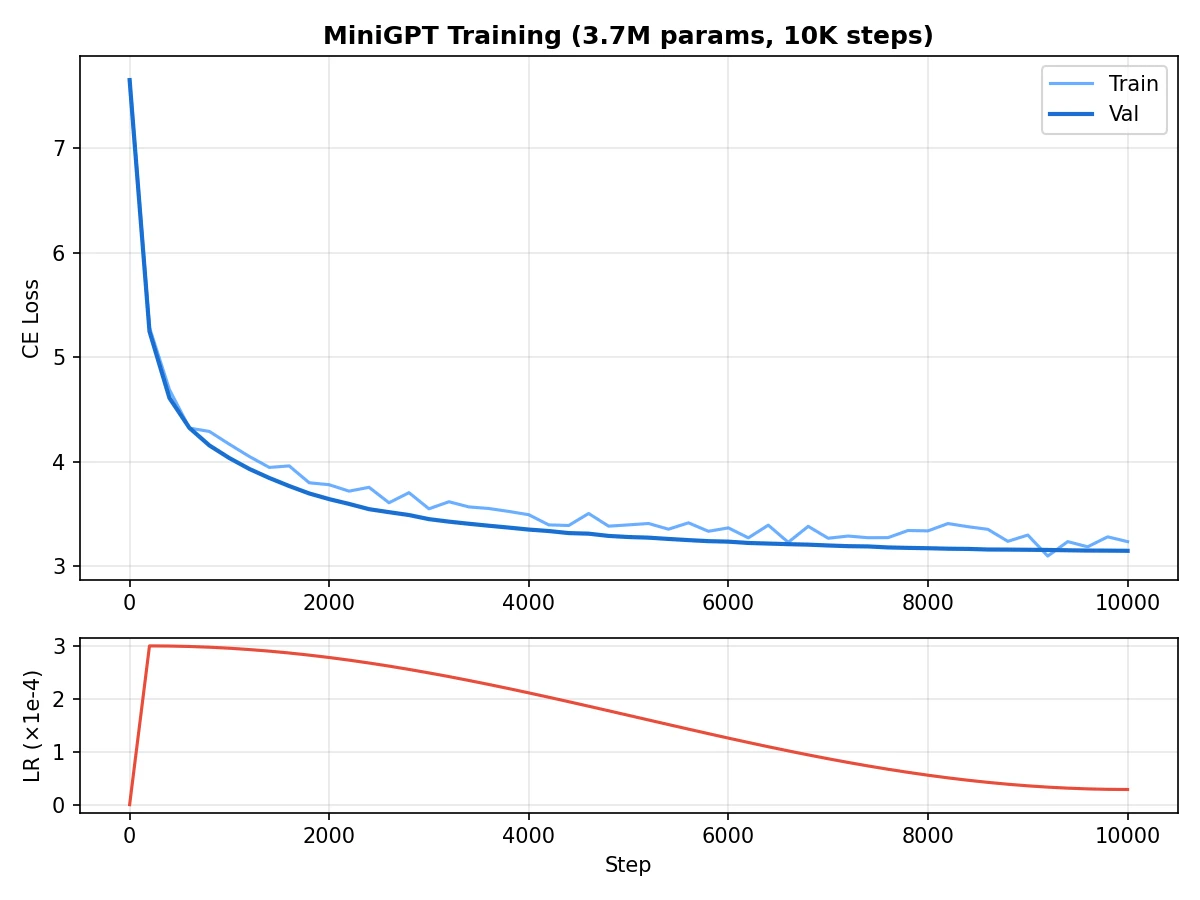
The loss curve had the shape I hoped to see: a sharp early drop during warmup, a long smooth descent, and then a flatter late stage as the learning rate decayed. The train-validation gap stayed small, which was a useful reminder that this model was not overfitting a tiny corpus so much as underfitting the structure of language.
Tokenizers Make Loss Hard to Read
My first mistake was almost evaluating tokenizers with raw validation loss. A character-level model produced the lowest raw loss, while an 8K BPE tokenizer produced the highest raw loss. If I stopped there, I would have concluded that character tokenization was best.
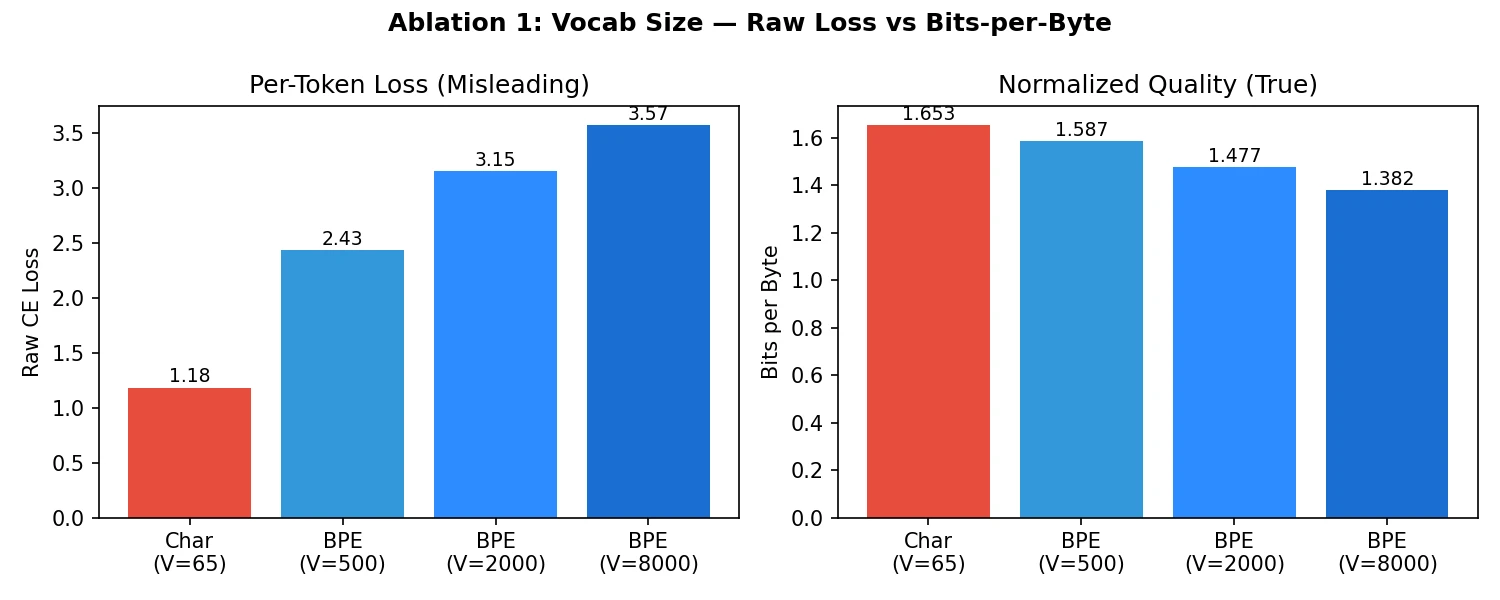
But raw per-token loss is not comparable across tokenizers. Predicting one of 65 characters is a different task from predicting one of 8,000 subwords. Once I normalized with bits-per-byte, the ranking reversed: the 8K BPE tokenizer was best, and the character model was worst.
This is the kind of bug that feels small but changes the entire conclusion of an experiment. The lesson was simple: when the unit of prediction changes, the metric has to change too.
The tokenizer also exposed some familiar failure cases:
- Numbers such as
1847split into individual digits. - Rare words such as
sesquipedalianfragmented into many subwords. - Non-English text paid a much higher token cost than English text.
That last point matters more than it looks. Tokenization is not just an implementation detail; it decides which languages and formats are cheap for the model to process.
Sampling Was Funny, But Useful
The generated text was not good in any practical sense, but it was good enough to reveal what the model had learned. At lower temperature, it produced grammatical but repetitive prose:
“She looked at him and Zossimov, who, then was uneasy, and was not going to see him. ‘You know, I’m not afraid of me?’ said Svidrigailov.”
Around temperature 0.8, it became more interesting. The model started stitching together character names, French place names, and dialogue-like syntax:
“The edge of the Rue de Theseigne of Aux-Meran, which was the cemetery, who was still more than M. sur M. de Villefort…”
At higher temperature, it became more creative and less coherent:
“It was a dark and ignorance at the dressing-room that I must rejoicate my son.”
The word “rejoicate” is exactly the kind of error I like seeing in small language models: wrong, but wrong in a way that shows the model has learned local morphology. It knows what English-ish words look like, even when it has no stable semantics behind them.
Width Beat Depth
I expected the deeper model to win when parameter count was roughly fixed. Instead, the shallow-wide model did better: 2 layers with 384 hidden dimensions beat 8 layers with 192 hidden dimensions, and it trained much faster.
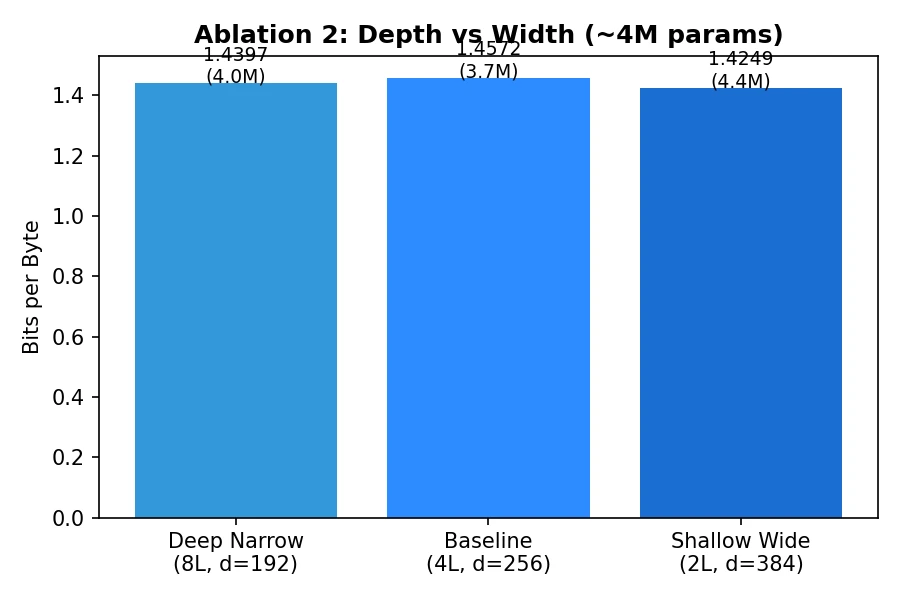
My interpretation is that at this size, the model benefits more from per-layer capacity than from long chains of composition. Wider layers also give each attention head more room. Depth probably becomes more important later, but at 4M parameters the sequential overhead is very real and the benefits are not fully unlocked.
Longer Context Was Faster
This was the most counter-intuitive result. I expected longer context to slow training down because attention is quadratic in sequence length. Instead, quality improved and throughput increased as context length grew from 64 to 512.
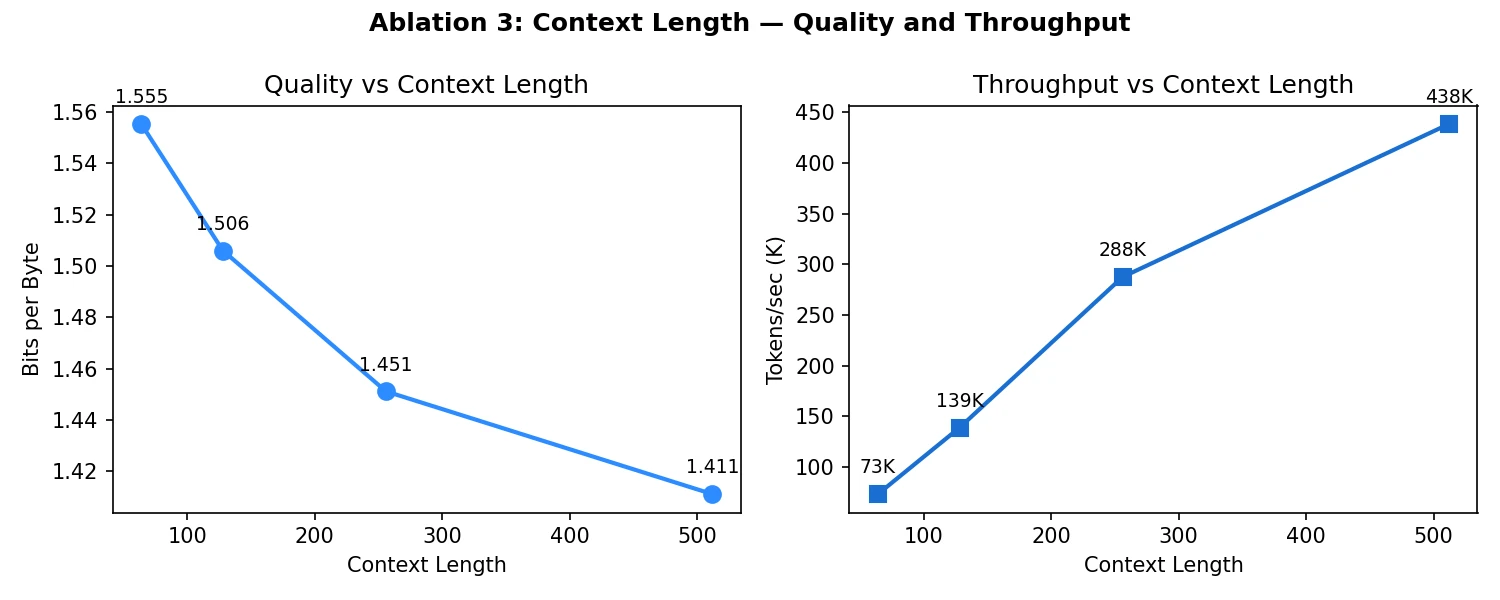
The reason is scale. On a 3.7M model, the GPU is not saturated at short context lengths. Longer sequences put more work into each batch and use the hardware better. The usual “long context is expensive” intuition is still true, but it is not the bottleneck in this toy regime.
Being Too Conservative Was Worse
The learning-rate sweep made the same point from another angle. I tried peak learning rates from 1e-5 to 3e-3. The low learning rates were not safer in practice; they were just undertrained.
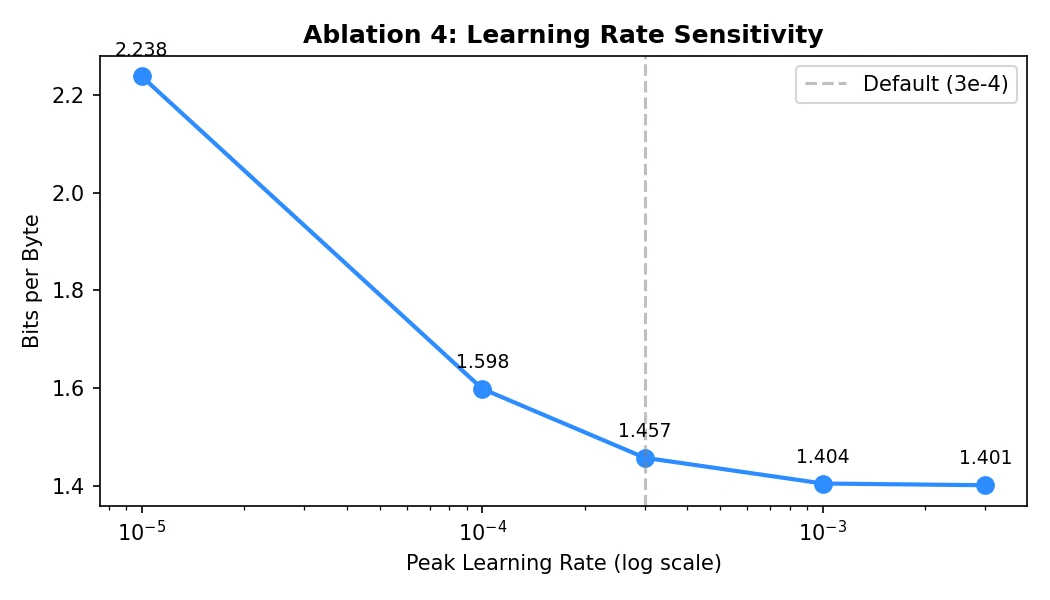
The jump from 1e-5 to 1e-4 mattered much more than the jump from 1e-3 to 3e-3. With gradient clipping, none of the runs diverged. For this short training budget, the bigger failure mode was not instability. It was moving too slowly.
What I Would Change Next
If I scaled this up by 10x, I would change several choices. I would use a larger BPE vocabulary, train longer, and move back toward deeper architectures once the model is large enough to benefit from them. I would also expect the learning-rate curve to shift: 3e-3 was fine here, but it may become unstable once the model is no longer this small.
The main thing I took away is that small-scale training is useful precisely because it is imperfect. It does not reproduce all the behavior of real LLM training, but it makes the tradeoffs visible. Tokenization, scaling shape, context length, and optimization are not separate knobs. Even in a 3.7M-parameter model, they interact in ways that can make an obvious-looking experiment point in the wrong direction.